melfeature¶
Content¶
Overview¶
melfeature allows to combine multiple analysis modules (such as histogram computation or statistical descriptors such as mean and variance) to module chains. Modules can be grouped in a serial or parallel fashion as shown in the following figure.
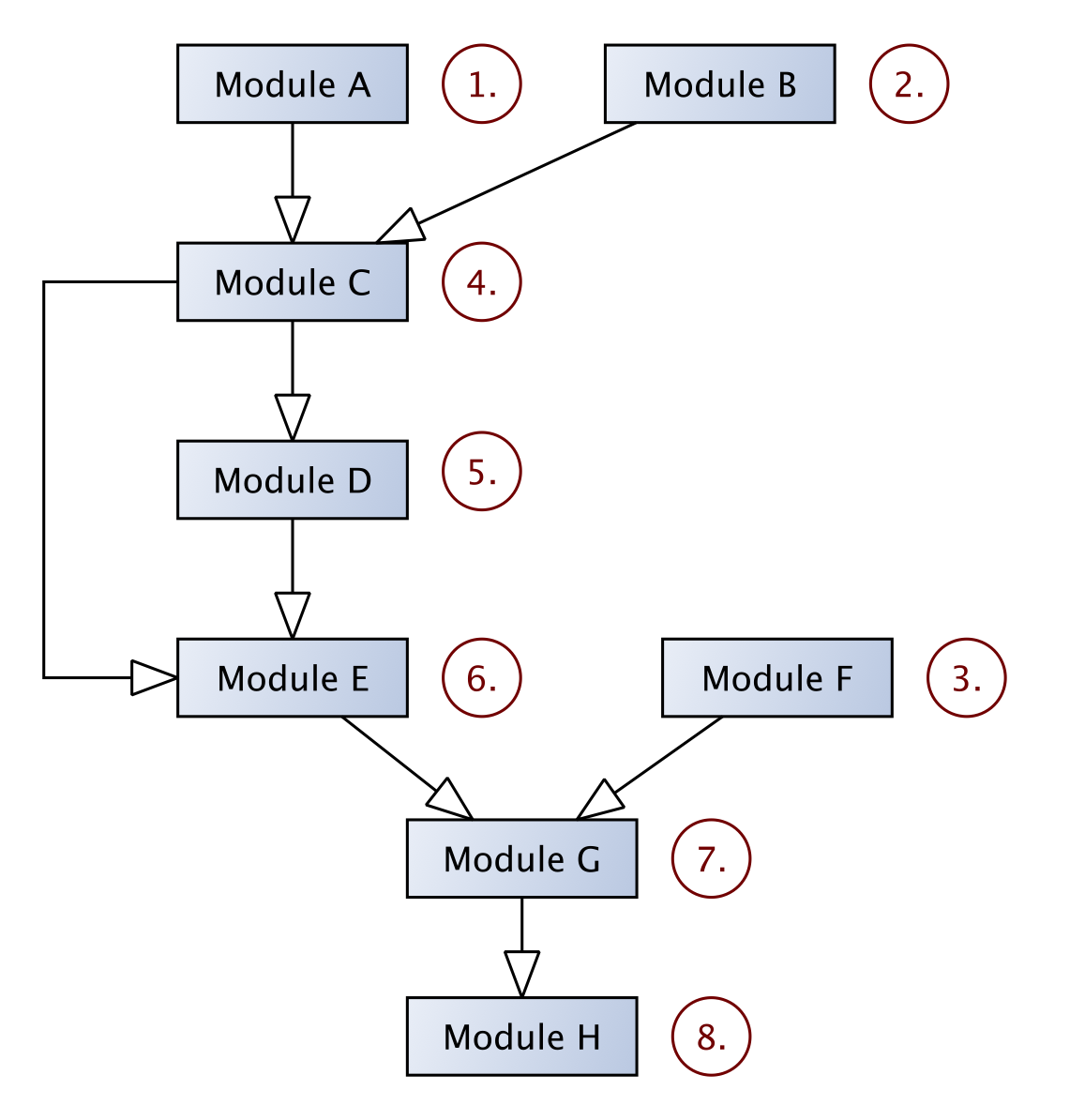
The processing order of all modules is determined automatically based on the dependencies between the modules. In the figure, the processing order is indicated using red font. A complete processing chain of modules will be hereafter called feature. Features are defined using specific configuration files, the so called Feature Definitions Files (FDF). Besides the comprehsensive set of pre-defined Feature Definition Files coming with the MeloSpySuite, user are free to modiy or define their own features definitions.
Please see also our Melfeature Tutorial for a more detailed introduction.
Input formats¶
melfeature reads the following input formats:
Weimar Jazz Database-Format (SQLITE3)
MIDI (monophonic)
MCSV (a CSV-based melody format)
MCSV2 (another CSV-based melody format)
EsAC (one melody per file)
SV project files
Output format is CSV (see Output Format).
Usage¶
Here is the basic call to melfeature:
melfeature [-h] [--version] [-d DIR] [-o OUTDIR]
[--feature_dir FEATURE_DIR] [-f FEATURE] [-c CONFIG]
[-s SVFILE] [--segmentation SEGMENTATION] [--shortnames]
[--convention CONVENTION] [--dbtype {SQLITE3}]
[--dbpath DBPATH] [--dbuser DBUSER] [--dbpwd DBPWD]
[positional]
Options and arguments¶
-
-h,--help¶ Show a help message and exits.
-
--version¶ Shows program’s version number and exit
-
-d<DIR>,--dir<DIR>¶ Use <DIR> as working directory for reading the project files. Default is the current directory.
-
-o<DIR>,--outdir<DIR>¶ Use <DIR> as directory to store extracted features as CSV file.
-
--feature_dir<DIR>¶ Use <DIR> as directory to load YAML files with feature definitions.
-
-f<FEATURE>,--feature<FEATURE>¶ Extract feature with label <FEATURE>.
-
-c<CONFIG>,--config<CONFIG>¶ Use the configuration file <CONFIG>, see below. The arguments <DIR> and <OUTDIR> override the settings in the config file, but the positional argument take precednec over the one specified in the config file.
-
-s<SVFILE>,--svfile<SVFILE>¶ Load the Sonic Visualizer SV file <SVFILE> as basis for feature extraction.
-
--segmentation<SEGMENTATION>¶ Extract features based on the segmentation <SEGMENTATION> (e.g., “phrases”)
-
--shortnames¶ Usually ferature label are constructed by the name of Feature Definition File and the feature label separated by a dot. If shortnames is set to True, only the feature label will be used.
-
--convention<CONVENTION>¶ Use convention <CONVENTION> (
de/en) for the syntax of the feature CSV file. German syntax uses commas as decimal separators and semicolons as field separators.
-
--dbtype{SQLITE}¶ Defines the database type.
-
--dbpath<DBPATH>¶ The directory that contains the database.
-
--dbuser<DBUSER>¶ Defines the database user.
-
--dbpwd<DBPWD>¶ Defines the database password.
Configuration file¶
Here is a typical example:
dir: /MYDIR/DB
feature_dir: /MYDIR/FEATURES/
outdir: /MYDIR/OUT/
outfile: features.csv
convention: de
shortnames: True
NA_string: NA
sample: 10
tunes:
- query:
conditions:
solo_info:
performer: '%'
display:
transcription_info: filename_sv
type: sv
features:
- GENERAL_SOLO_METADATA: performer, title
- PITCH_FEATURES
- IOICLASS_RUNLENGTH: ~aic_seg_len, ~ric_seg_len
segments:
- phrases
# - bars: chunks 8 4
# - chorus: 1 2
# - form: A1 A2 B3
# - chunk: 32
# - chords: G7
# - ideas
database:
type: sqlite3
path: wjazzd.db
password: None
use: True
content-type: sv
version: 2
Explanation¶
General parameters¶
In the head of the configuration file, general parameters such as dir, feature_dir, outdir, and outfile are set. They bear the same meaning as the corresponding
commandline options (cf. Options and arguments). The field convention and shortnames have the same meaning as the corresponding command line parameters. For both the commandline specification
takes precedence. The NA_string fiekd allows to specify which value should be used for uncalculatable or otherwise not retrievable features. This might come in handy for further processing
with statistical software.
The fields sample and seed allow to draw a random sample of the size following after sample (here 10) from the full set of data as specified in the data selection section.
seed sets the internal random seed for the random generator to a certain value to make drawing random samples reproducible.
Data selection¶
Under the section tunes an arbitrary list of input files can be specified. There are two basic possibilities: Reading from files or from a database. tunes starting with the
keyword file are read from files as specified by the following value (use of wildcards is permitted), and tunes starting with query are read from a source database as specified
in the section database. See Query block syntax for more information how to write database queries.
In this example, all the query determines to retrieve all songs in the database, since the field performer is specified as ‘%’, which is a wildcard matching all strings, hence all
performer names. The files will be represented in the output file with their filename_sv values, which is part of the table transcription_info in the database (cf.
SQLITE3 database formats)
The block for database is used to read from a database. In this case, the flag use must be set to True, otherwise the section and any query-definitions will be ignored.
If a database is to be used, all file sets in the files sections are ignored and only the query sections are considered. Likewise, if no source database is used
(parameter use is set to False), all query entries are ignored.
In this example, the database wjazzd.db is searched in the directory /MYDIR/DB as specified in the dir block at the beginning of the file.
Feature selection¶
In the section features, the list of features to be extracted is defined. For each feature in the list, a corresponding YAML file in the directory feature_dir must exist,
otherwise the feature will be ignored. melfeature tries to extract all features that are usable, and issues a warning if some feature could not be found. After the
name of the FDF, an optional colon followed by a comma-separated list of features names can follow. These have correspond to sink labels in the specified FDF. If this optional list
is absent, melfeature will compute all features defined in this FDF. Specific features can also be excluded by preceding the name with a ~ sign. Mixing of including and excluding
feature labels will result in using all included features.
In the example above, only two features (performer, title) of all 16 possible features from GENERAL_SOLO_METADATA.yml are used, which refers to the solo metadata stored in the database,
all features from the FDF PITCH_FEATURES.yml are extracted, and for IOICLASS_RUNLENGTH the two features aic_seg_len and ric_seg_len are excluded.
The convention is to name FDF with capital letters and feature labels with lower case underscored names.
A detailed explanation on how to write your own feature definition files is provided here.
Segmentation¶
In the section segments, a segmentation can be defined to be used for feature extraction, Available segmentations are phrases, bars, chorus, form
chords, chunks. These can be followed by a space separated list of optional parameters that can be used to specify subsets. See Available Segmentations for details.
In the example above, phrases is defined as segmentation. Hence, all specified features will be computed for each phrase in each solo. For each phrase a line with feture values will
be written in the output file, where the display name is appended by a suitable ID, in this case the phrase ID. For example, Miles’ solo on “So What” will generate lines with IDs
MilesDavis_SoWhat_PREFINAL.phrase.1.sv, MilesDavis_SoWhat_PREFINAL.phrase.2.sv etc. followed by the feature values for the corresponding phrases. If more than one segmentation is
specified, melfeature will try to compute a intersection of segments, which might not always be successful, e.g., if phrases 1 and 2 are requested but at the same time chorus 2, the
intersection will be empty.
Segmentation |
Optional Parameters |
Explanation |
|---|---|---|
|
Phrase IDs |
Phrases of the solo as annotated and stored in the database. Phrases are enumerated starting with 1. |
|
Space separated integer spans or |
Single measures of the solo as specified. |
|
Chorus IDs |
Single choruses of the solo as annotated. Choruses are enumerated starting with 1. |
|
Form specifiers |
Single form parts. Form parts are specified using the the MeloSpy syntax for Forms. |
|
Chord symbols or |
Extracts seqments according to the specified chords. Chords are specified using the MeloSpy syntax for Chords . |
|
chunk size, hop size |
Chunks are subsequences with a length (number of tone events) as specified in chunk size. The are calculated starting from the first event my moving a window along the event sequence, where each chunk is hop size events away. |
|
– |
Only for WJazzD solos and SV project files. The segmentation consists of a enumerated sequence of midlevel units. |
Database parameters¶
In the section database, the parameters (type, password) for database access as well as the database name (path) is defined. The parameters use enforces the usage of the database as data source. For the new
database version 2 of the Weimar Jazz Database content-type: sv and version: 2 should be specified.
Output Format¶
Since v1.1.6 of melfeature (as contained in MeloSpySuite v1.4), two CSV-based output formats are supported, the new long format (default) and the old wide format.
Common elements¶
Both out formats are CSV files of a certain structure. The first line is the header, describing the single columns. The first column is the ID, mostly the filename or the value specified in a
database query. If segmentation is used, appropiate extensions are added, e.g., MilesDavis_SoWhat_PREFINAL.phrase.1.sv for the first phrase in Miles Davis solo on “So What”. The other
header columns contain the feature labels, either in long or short form. Long form is composed of <FEATURE DEFINITION FILE>.<FEATURE LABEL>, e.g., PITCH_RANGE.pitch_range for pitch range
in the example above. Columns are always separated with semicolons, independent of convention. Decimal values are written with dot . in the English (default) convention, and with comma ,
in the German convention.
If segmenation was used, there will be two more columns, if the global parameter split_ids is set to True (which is the default). These columns are named seg_type and seg_id.
The first column will contain a string specifying the employed segmentation (e.g. phrases), the second will contain an identification of the segments, depending on the segmentation type.
If split_ids was set to False, these segmentation values will be concatenated separated with dots to the values in the id column.
Feature values can also be vectors (list of scalars) and matrices (list of vectors). The difference in long and wide format consist in handling these non-scalar features. Hence, both formats are identical for pure scalar features.
Long format¶
In long format, all entries of a vector feature occupy one row as do of course scalar features. Identic scalar values are copied in each row. For vector of different lengths, the shorted vectors are appended with NAs up to the lenght of the longest vactor features. Matrix-valued features are not supported in long format. melfeature will issue an error, if these are tried to write to long format.
Wide format¶
In wide format, vector and matrix-values features are compactified to strings using separated list of components. The choice of field separators depend on the overall convention specified for the output (dot or comma as decimal point).
Components of a vector are separated with a comma , in the English convention and with a colon : in the German convention.
The vectors of a matrix are separated by a colon``:`` in the English convention and by a pipe symbol | in the German convention. The following table gives an overview of the separators
used in the different conventions.
Separator |
English Convention |
German Convention |
||
|---|---|---|---|---|
Field separator |
Semi-colon |
|
Semi-colon |
|
Decimal |
Dot |
|
Comma |
|
Vector components |
Comma |
|
Colon |
|
Matrix components |
Colon |
|
Pipe |
|