The PATTERN tabs¶
In the PATTERN tabs, you can define the parameters for the three melpat modes
SEARCH - Specific patterns can be searched across the repository of melodic sequences.
DATABASE - All information about all N-grams occurring in the selected pieces using the specified transformation are retrieved.
PARTITION - Retrieve all patterns for a piece according to certain specifications and with respect to all other pieces.
Note
A detailed description of melpat and all three modes is given here.
You can start melpat using the Start Processing button in the bottom and open the result folder using the Open Result Folder button.
Here are screenshots of the three PATTERN modes in the program:
SEARCH Mode¶
A search can have two parts: a primary search and secondary search. For primary search you have specify first the basic transformation to be used (e.g., MIDI pitch, intervals chordal pitch class). here is a list of Suitable transformations. Next, a search pattern has to be specified, where the syntax is based on the transformation in use and Python regular expressions, a powerful and fast tool for very general searches. See Search pattern syntax and Primary search specification for a detailed description. Optionally, you can specify a secondary search which searches the result set of the primary search. For this, you can specify another transformation and another search string as well as an operation how to filter the primary result set, see Secondary search specification for a list of options and it functions. Finally, you can choose your favourite mode of how the results should be saved, options are List, Stats, and MIDI. See Search mode for more details.
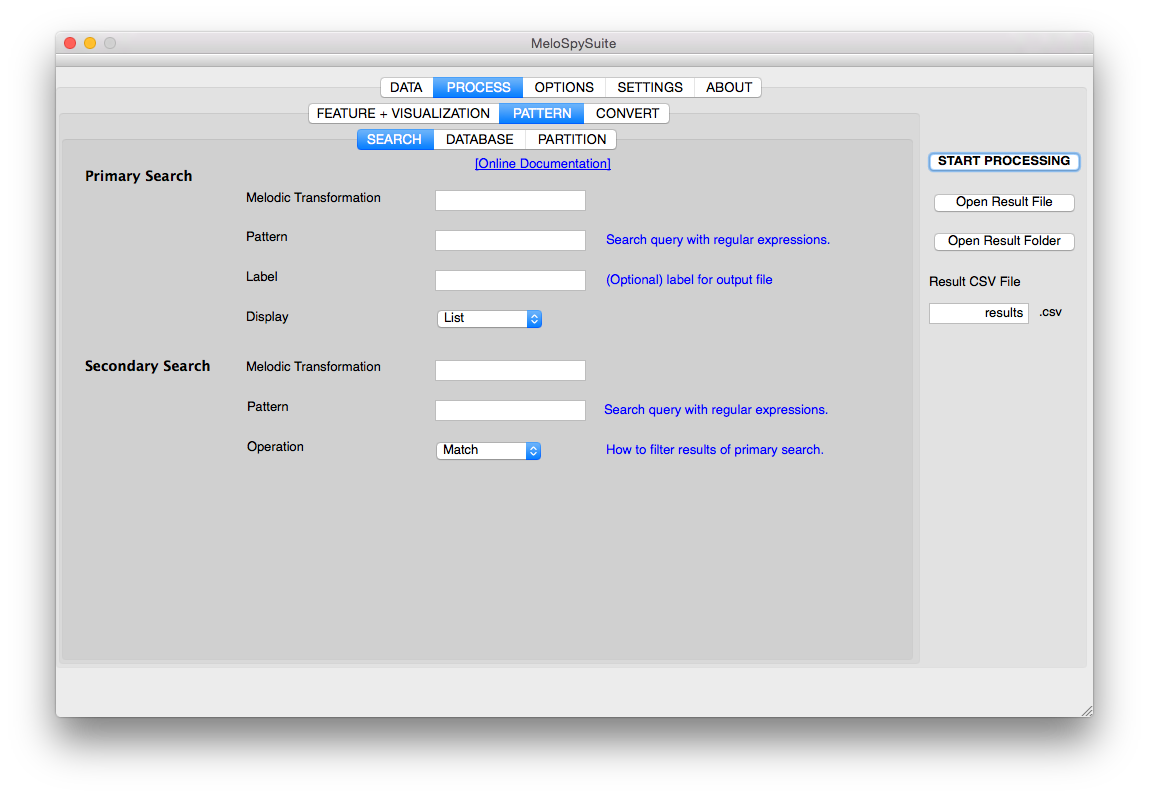
DATABASE Mode¶
Database mode retrieves all possible patterns of a certain transformation in the repository of melodies between a minimum and a maximum length. Amongs other purposes, this allows to find (empirical) Markov transition probabilities of arbitrary order, since the frequencies of N-grams are equivalent to Markov probabilities of N-1 order. See Database mode for more information.
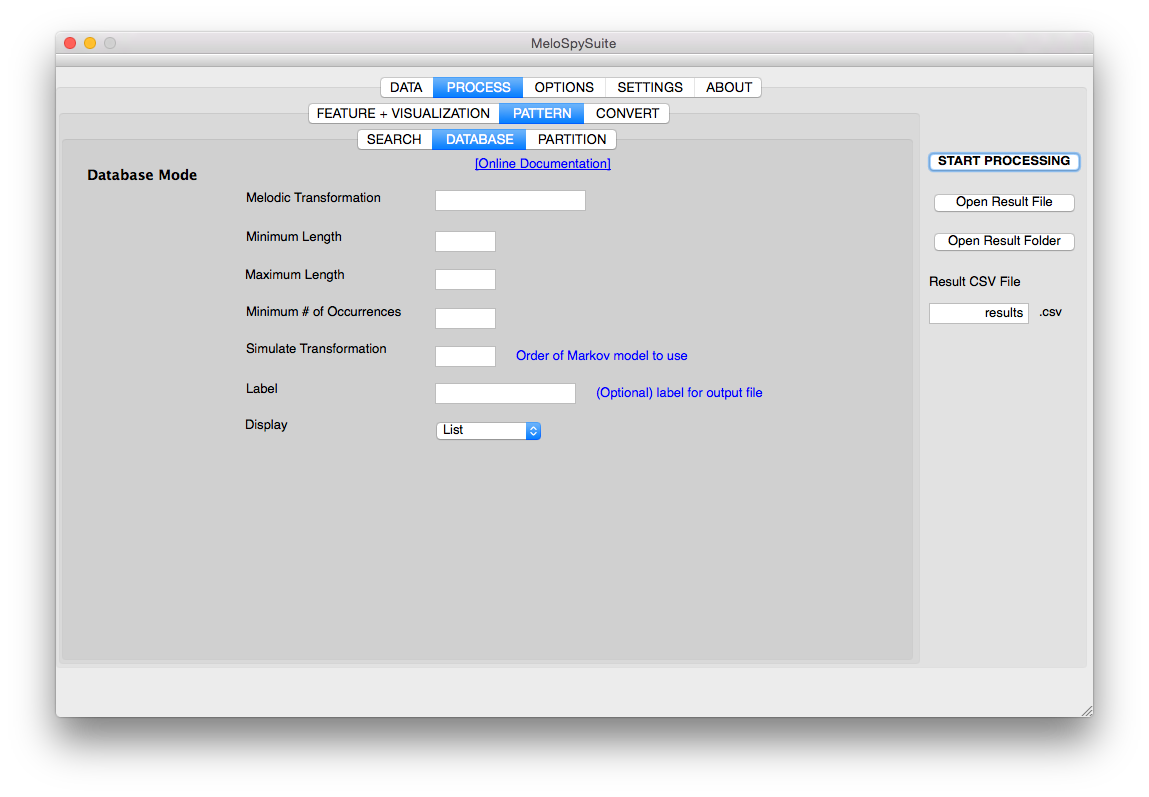
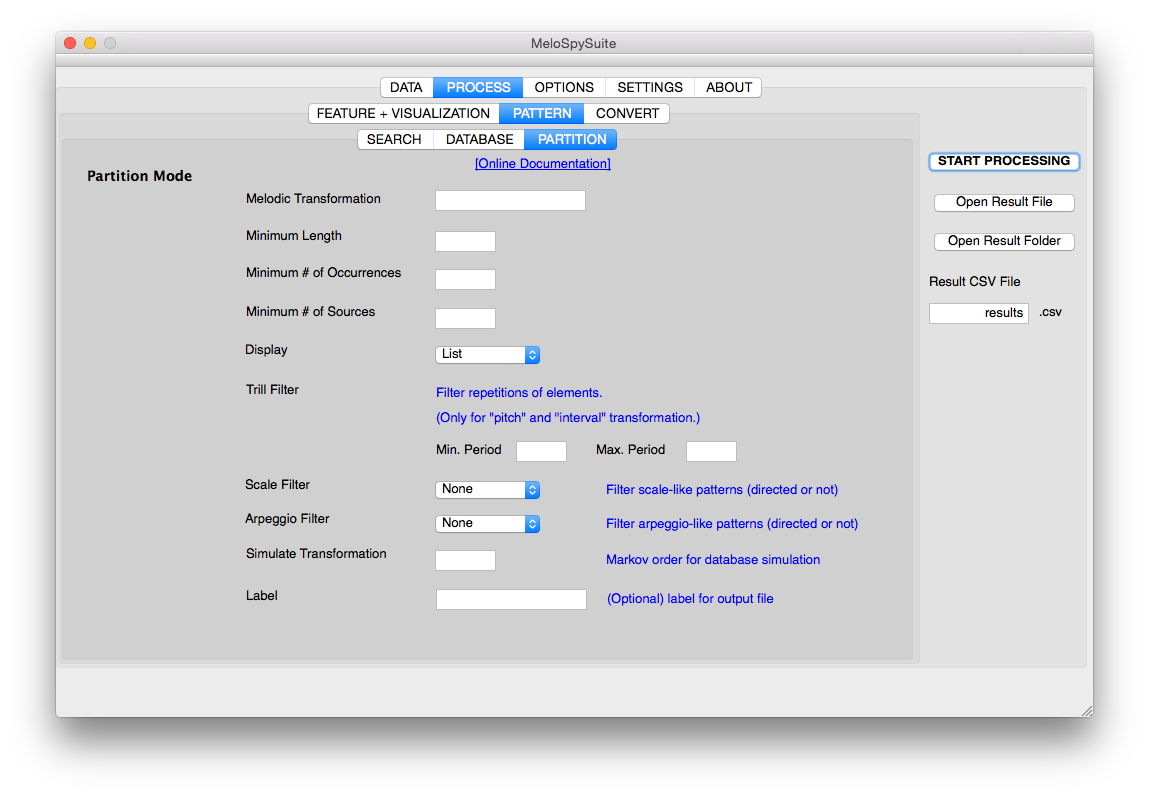
PARTITION Mode¶
Partition mode is designed for finding pattern partitions of single pieces, i.e., complete lists of all real patterns occurring in a melody, but with respect to all other melodies in the repository. The difference between partition mode and database mode lies in the filtering of sub-patterns and special patterns, which is not done in database mode. Morever, the focus lies on single pieces in parititon mode, whereas in database mode the focus is more on the repository as a whole. Accordingly, slightly different sets of criteria are available. For partition mode, these are minimal and maximum length (N), minimal number of occurrences (total frequency in the whole repository) and minimum number of different sources (i.e., number of different melodies where a pattern should be found). Sub-patterns are filtered out, unless they do not occur somewhere else outside the surrounding pattern, hence, having a “life” on their own. This filter feature reduces the result set vastly. Furthermore, options exists to filter out patterns of lesser interest, i.e., trills, scales sections and arpeggios. Partition can be stored as Lists (every pattern listed) or just with a set of Stats for each partition. See Partition mode for more information.
Next part: The CONVERT tab